
¿Qué es Spinnaker? Una herramienta DevOps para desplegar a producción rápido, seguro y repetible

Spinnaker es una plataforma de entrega continua de código abierto para liberar cambios de software con alta velocidad y confianza. A través de una poderosa capa de abstracción, Spinnaker proporciona herramientas nos permiten llevar el código de la aplicación desde el “commit” hasta producción. Es considerada la plataforma de entrega continua más madura y tiene la experiencia de los equipos de Netflix, Google, Microsoft y Amazon pues la usan en su ciclo de desarrollo de software. Las empresas que lo usan para liberar aplicaciones a producción incluyen Target, Salesforce, Airbnb, Cerner, Adobe y JPMorgan Chase.
Al día de hoy soporta las siguientes nubes:

¿Porqué usar Spinnaker?
Podemos manejar nuestro Systems Development Life Cycle, también conocido como ciclo del desarrollo de software en Spinnaker utilizando la GUI (interfaz gráfica de usuario) o config-as-code. Podemos ver, administrar y crear flujos de trabajo de aplicaciones que involucren uno o todos estos recursos:
- Implementaciones de máquinas virtuales (VM) en un proveedor de nube pública, “integradas” como infraestructura inmutable
- Despliegue de contenedores en una nube
- Despliegue de contenedores en Kubernetes
- Balanceadores de carga
- Grupos de seguridad
- Grupos de servidores
- Clusters
- Firewalls
Como dice el mismo sitio de Spinnaker, creamos un “camino pavimentado” para la entrega de aplicaciones, con protecciones que aseguran que solo la infraestructura y configuración válida alcancen producción.
Características
Multi-Nube
Soporta múltiples proveedores de nube, incluidos AWS EC2, Kubernetes, Google Compute Engine, Google Kubernetes Engine, Google App Engine, Microsoft Azure, Openstack, Cloud Foundry y Oracle Cloud Infrastructure, con DC / OS próximamente.
Liberación automatizadas
Soporta pipelines de implementación que ejecutan pruebas de integración y puede activar y desactivar grupos de servidores así como supervisar las implementaciones. Escucha eventos, recolecta artiacts y activa pipelines de Jenkins o Travis CI. También se admiten triggers a través de git, cron o el push de una nueva imagen en un registro de docker.
Integraciones de monitoreo
Se integra con servicios de monitoreo; Datadog, Prometheus, Stackdriver, SignalFx o New Relic utilizando sus métricas para el análisis canario.
Notificaciones
Integración para notificaciones de eventos por correo electrónico, Slack, HipChat o SMS (a través de Twilio).
VM Bakery
“Hornea” imágenes de VM inmutables a través de Packer, que viene empaquetado con Spinnaker y ofrece soporte para plantillas de Chef y Puppet.
Estrategias de implementación
Configura pipelines con estrategias de implementación como highlander y red/black o blue/green deployment. Soporte para Canary releases.
Jenkins vs Spinnaker
Spinnaker no es una herramienta de construcción (Build) , sino una herramienta de implementación, con un enfoque en la nube. Jenkins es para CI (Integración continua) y necesita scripts y complementos para hacer CD (Despliegue continuo).
Spinnaker no reemplaza por completo a Jenkins en un pipeline de CI/CD, pero tiene integraciones nativas hacia la nube y con capacidades extendidas. Spinnaker se creó para combinar CI y CD para lograr implementaciones optimizadas en la nube. Si bien Jenkins nos puede ayudar a desplegar sofware, no se construyó con esos fines y necesita mucha mano para lograrlo. Spinnaker ofrece soporte integrado para hacer cosas como crear balanceadores de carga, redimensionar clústeres y ejecutar rollbacks.
Spinnaker ofrece soporte nativo para implementaciones básicas y avanzadas sin la necesidad de código y scripts personalizados como necesita Jenkins.
Entones, antes teniamos: Jenkins + Ansible + proveedor de la nube para hacer un pipeline de CI/CD completo.
Hoy, podemos centralizar todos los pasos desde Spinnaker pues podemos mandar llamar a Jenkins y monitorearlo desde el tablero de Spinnaker.
En conclusión: es correcto usar Jenkins y Spinnaker, cada quién a lo suyo, pero podemos gestionar todo el pipeline desde Spinnaker delegando tareas a Jenkins.
Terminología de Spinnaker
Spinnaker tiene 2 capacidades diferentes: realizar la gestión de aplicaciones y la implementación de aplicaciones .
Gestión de aplicaciones
Spinnaker puede ver y administrar los recursos en la nube. Las organizaciones modernas operan colecciones de servicios, a veces denominadas “aplicaciones” o “microservicios”. Una aplicación de Spinnaker modela este concepto.
Las aplicaciones, los clústeres y los grupos de servidores son los conceptos clave que Spinnaker usa para describir los servicios. Los balanceadores de carga y los firewalls describen cómo los servicios están expuestos a los usuarios.
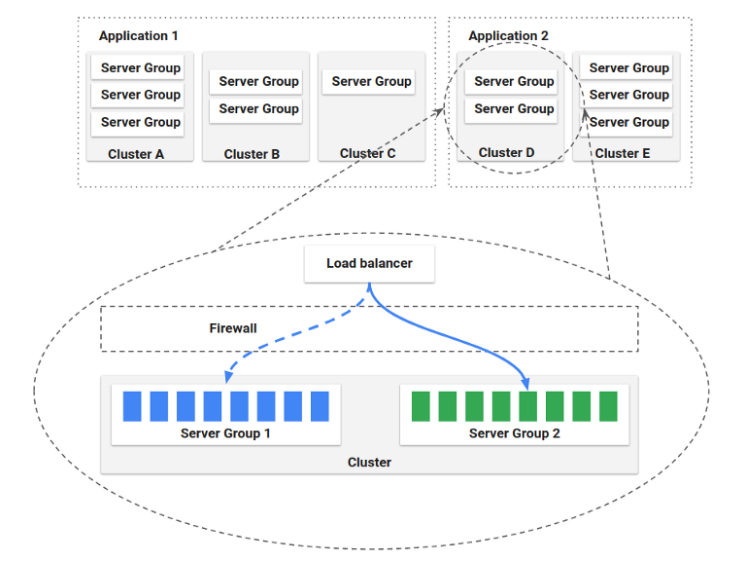
Aplicación
Una aplicación es una agrupación lógica de servicios que tiene que implementar Spinnaker, incluye una colección de clústeres, que a su vez son colecciones de grupos de servidores. Tambiénse puede incluir firewalls y equilibradores de carga.
Podemos entender una aplicación como un servicio, es decir, una sola aplicación puede asignarse a un microservicio, aunque spinnaker no lo impone.
Clúster
Varios servidores es un grupo de servidores, mientras que un clúster es un conjunto de grupos de servidores.
Grupos de servidores
Es el recurso base, un grupo de servidores identifica el artefacto desplegable para la aplicación como una imagen de VM o una imagen de Docker además de sus configuraciones como número de instancias, políticas de autoescalado, metadatos, etc.
Ejemlpos de esto son deslplegar una VM (En este caso el grupo des de 1) o Dos VMs. También pueden ser 1 o 2 pods/containers de k8s.
LoadBalancer
Un Load Balancer está asociado con un protocolo de ingreso y un rango de puertos. Maneja el tráfico entre instancias en los grupos de servidores.
Firewall
Un conjunto de reglas de firewall para políticas de acceso a la red.
Implementación de aplicaciones
Utilizamos las funciones de implementación de aplicaciones de Spinnaker para construir y administrar flujos de trabajo de entrega continua.
Pipeline
Un pipeline es el componente clave de gestión de despliegues en Spinnaker. Consiste en una secuencia de acciones, conocidas como etapas. Podemos pasar parámetros de etapa en etapa a lo largo del pipeline.
Podemos iniciar un pipeline manualmente, o podemos configurarlo para que se active automáticamente por un evento, como la finalización de un trabajo de Jenkins, una nueva imagen de Docker que aparece en el registro, un evento de CRON o una etapa en otro pipeline.

Etapa
Una etapa en Spinnaker es una colección de tareas que describen una acción de nivel superior que el pipeline realizar. Podemos secuenciar etapas en un pipeline en cualquier orden.
Spinnaker ofrece una serie de etapas, como desplegar , escalar recurso, eliminar recurso, desactivar recurso, juicio manual, analisis canario, ejecutar Job de Jenkinks, y muchas más. La lista completa la puedes consultar aquí.
Tarea
Una tarea en Spinnaker es una función a realizar.
Componentes de Spinnaker
¿Cómo está hecho Spinnaker? Se compone de una serie de microservicios :
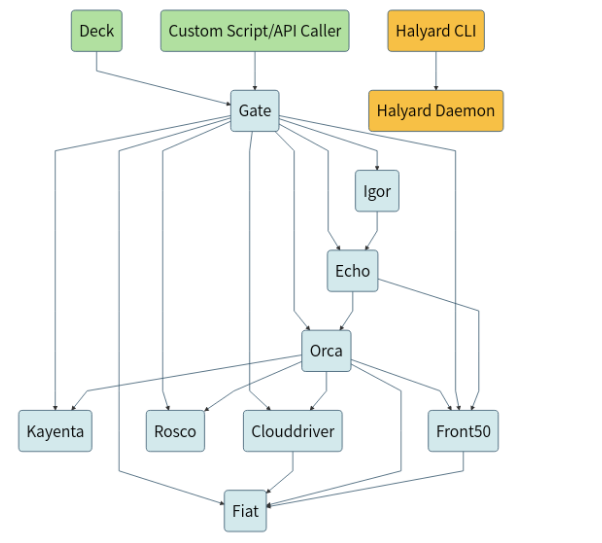
- Deck es la interfaz de usuario (UI) para acceder desde navegador.
- Gate es la e API. La interfaz de usuario de Spinnaker y todos los componentes que llaman a Spinnaker lo hacen a través de Gate.
- Orca es el motor de orquestación. Maneja todas las operaciones y pipelines.
- Clouddriver es responsable de todas las llamadas hacia los proveedores de nube y de indexar / almacenar en caché todos los recursos desplegados.
- Front50 se utiliza para persistir los metadatos de aplicaciones, piplenes, proyectos y notificaciones.
- Rosco es el componente que se utiliza para “Bakeru”. Se usa para producir imágenes de máquinas(por ejemplo, imágenes GCE, AWS AMI, imágenes de Azure VM) Actualmente es un wrapper para Packer de Hashicorp, pero se ampliará para admitir otros plugins para producir imágenes de VM.
- Igor se usa para activar (trigger) pipelines a través de trabajos de integración continua en sistemas como Jenkins, Travis CI y Docker Registry
- Echo es el bus de eventos de Spinnaker. Admite el envío de notificaciones (por ejemplo, Slack, correo electrónico, Hipchat, SMS) y actúa en los webhooks de servicios como GitHub.
- Fiat es el servicio de autorización de Spinnaker. Se utiliza para consultar los permisos de acceso de un usuario para cuentas, aplicaciones y cuentas de servicio.
- Kayenta proporciona análisis canario automatizado para Spinnaker.
- Halyard es el servicio de configuración de Spinnaker. Halyard gestiona el ciclo de vida de cada uno de los servicios anteriores. Es la herramienta con la que instalamos Spinnaker.
Además, Spinnaker utiliza Redis como un motor de almacenamiento en caché para almacenar información relacionada con la infraestructura, almacenar ejecuciones en vivo, devolver definiciones de pipelines más rápido, etc.
Consideraciones sobre la instalación de Spinnaker
El proceso de instalación es el siguiente:
1. Instalar Halyard
Debemos contar con el CLI de Hayard instalado.
2. Elegir proveedores de nube
En Spinnaker, los proveedores son integraciones a las plataformas en la nube en las que implementan las aplicaciones.
En esta etapa,se registran las credenciales para las plataformas en la nube. Esas credenciales se conocen como Cuentas en Spinnaker.
Todas las abstracciones y capacidades de Spinnaker se basan en los proveedores de la nube que admite. Entonces, para que Spinnaker haga algo, debemos habilitar al menos un proveedor, con una cuenta agregada para ello.
Podeos agregar tantos proveedores como queramos, de los siguientes :
- App Engine
- Amaozon EC2 y ECS
- Azure
- Cloud Foundry
- DC / OS
- Google Compute Engine
- Kubernetes
- Oracle
3. Eligir un entorno
Debemos elegir un entorno, las opciones son:
Instalación distribuida en Kubernetes
Halyard despliega cada uno de los microservicios de Spinnaker por separado. Esto es muy recomendable para su uso en producción.
Instalaciones locales de paquetes Debian
Spinnaker se implementa en una sola máquina, basada en Debian o Ubuntu. La instalación de Debian local significa que Spinnaker se descargará y ejecutará en la máquina en la que Halyard está instalado actualmente. Se Recomendia al menos 4 núcleos y 16 GB de RAM.
Nota: La instalación local de Debian requiere Ubuntu 14.04 o 16.04.
4. Eligir un servicio de almacenamiento
Spinnaker requiere un proveedor de almacenamiento externo para mantener la configuración de las aplicaciones y los pipelines.
Spinnaker es compatible con los proveedores de almacenamiento que se listas a continuación. La opción que elija no afecta la elección de proveedor de la nube. Es decir, podemos usar Google Cloud Storage como fuente de almacenamiento pero implementar aplicaciones en Microsoft Azure.
Soluciones de almacenamiento compatibles:
- Azure Storage
- Google Cloud Storage
- Minio
- Amazon S3
- Oracle Object Storage
5. Implementar y conectar
Finalmente elegimos una versión e instalamos. Spinnaker no se bindea en las IPs públicas, sino que está disponible en localhost. Para cambiar esto, consulta el procedimiento aqui. Las opciones de autenticación se listan en este enlace.
Si te pareció útil, por favor comparte. Si tienes dudas , no dudes en escribirme en los comentarios o a través de redes sociales.
Referencias:
https://medium.com/searce/spinnaker-the-hard-way-278913f3f1d8