Comparación de Bases de Datos en Google Cloud: Datastore vs BigTable vs Cloud SQL vs Spanner vs BigQuery
Después de mucho tiempo, millones de dólares inversión y clientes de referencia en cada vertical importante, Google Cloud Platform finalmente se ha convertido en un competidor muy importante para Amazon Web Services y Microsoft Azure cuando se trata de infraestructura de nube. Si bien las ofertas de computo y almacenamiento de Google Cloud son más fáciles de entender, comprender las diferentes ofertas de bases de datos administradas no es tan sencillo. Estoy preparándome para tomar la certificación de Professional Cloud Architect y como parte de mi material de estudio realicé la siguiente comparación de los servicios de bases de datos y sus casos de uso.
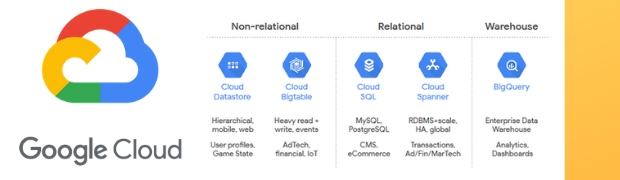
Cloud Datastore
Base de datos NoSQL altamente escalable con modelo de datos de documento, transacciones atómicas (pero no totalmente ACID), lenguaje de consulta tipo SQL y soporte para configuraciones región/multirregión. Escala a Terabytes. Solo tiene transacciones atómicas y duraderas (lo que significa que no hay consistencia ni aislamiento). A diferencia de BigTable, Datastore está optimizado para un conjunto de datos más pequeño.
Casos de uso principales: Alta transaccionalidad, aplicaciones existentes con datos de aplicación semiestructurados y datos jerárquicos, aplicaciones móviles y frameworks de desarrollo web. Más información en la documentación oficial de Google Cloud Datastore
Extra ¿Qué es ACID?
ACID (Atomicidad, consistencia, aislamiento, durabilidad) es un conjunto de propiedades de transacciones de base de datos destinadas a garantizar la validez incluso en caso de errores. Una secuencia de operaciones de base de datos que satisface las propiedades de ACID (y estas pueden percibirse como una sola operación lógica en los datos) se llama una transacción. Por ejemplo, una transferencia de fondos de una cuenta bancaria a otra.
Cloud Bigtable
Base de datos NoSQL con modelo de datos widecolumn, de una sola región y altamente escalable con baja latencia y alto rendimiento. Profundamente integrado con el ecosistema de Hadoop, incluida la compatibilidad de su API con la de HBase. Es bueno para aplicaciones de procesamiento analítico/transaccional. La usan los servicios internos de Google como la Búsqueda de Google, Google Maps y Gmail. Escala a Petabytes.
Casos de uso principales: Aplicaciones que tienen una ingesta de datos frecuente, maneja millones de operaciones por segundo. Gran volumen de datos en Industrias financiera, advertising, IoT. Sistemas de personalización y recomendaciones, conjuntos de datos geoespaciales y gráficos. Más información en la documentación oficial de Google Cloud BIgtable
Extra ¿Qué es un modelo widecolumn?
Un almacén de columna ancha es un tipo de base de datos NoSQL que utiliza tablas, filas y columnas, pero a diferencia de una base de datos relacional, los nombres y el formato de las columnas pueden variar de una fila a otra en la misma tabla. Un almacén de columna ancha se puede interpretar como un almacén de valor-clave bidimensional. Amazon DynamoDB, Apache Accumulo, Apache Cassandra, Apache HBase y Azure Tables son ejempos de otras bases de datos widecolumn
Cloud SQL
Es un RDMBS en alta disponibilidad que básicamente ofrece MySQL y PostgreSQL monoliticos como servicio administrado. No escala horizontalmente y su capacidad llega a un máximo de 10TB de almacenamiento y 416 GB RAM. Es totalmente ACID compliant.
Casos de uso principales: Es mejor para aplicaciones OLTP web y las aplicaciones existentes CRM, ERP, etc. Más información en la documentación oficial de Google Cloud SQL
Extra ¿Qué es OLTP?
Procesamiento de transacciones en línea, se caracteriza por un gran número de transacciones cortas (INSERTAR, ACTUALIZAR, BORRAR). El énfasis principal de los sistemas OLTP es en el procesamiento de consultas rápidas pero no complejas, manteniendo la integridad de los datos en entornos de acceso múltiple.
Cloud Spanner
Un RDMBS también para aplicaciónes OLTP pero que necesiten una base de datos globalmente distribuida y altamente escalable. Cuenta con escalamiento horizontal y sopporta Multiregion. Escala a Petabytes y es ACID compliant.
Casos de uso principales: Aplicaciones OLTP distribuidas, como catálogo de productos de retail, aplicaicones SaaS y juegos en línea. Más información en la documentación oficial de Google Cloud Spanner
Extra ¿Qué es un RDMBS?
Los sistemas de gestión de bases de datos relacionales (RDBMS) son compatibles con el modelo de datos relacional, orientado a tablas. El esquema de una tabla, se define por el nombre de la tabla y un número fijo de atributos con tipos de datos fijos. Un registro o entidad corresponde a una fila en la tabla y consta de los valores de cada atributo.
BigQuery
Este es más bien un sistema de datawarehouse, de hecho Google lo coloca en los productos de Bigdata y no de almacenamiento, básicamente es una base de datos Relacional SQL. A diferencia de BigTable, se enfoca en los datos en una imagen grande y puede consultar un gran volumen de datos en poco tiempo. Como los datos se almacenan en un formato de datos en columnas, es mucho más rápido en el escaneo de grandes cantidades de datos en comparación con BigTable.
BigQuery es realmente para el tipo de consulta OLAP y escanea una gran cantidad de datos y no está diseñado para consultas de tipo OLTP. Cómo comparación para pequeñas lecturas/escrituras, toma aproximadamente 2 segundos, mientras que BigTable toma aproximadamente 9 milisegundos para la misma cantidad de datos.
Casos de uso principales: elegir para exploración y procesamiento de macrodatos, línea, sistema de procesamiento con petabytes de escala, almacén de datos empresariales para análisis, generación de informes de estadísticas de grandes volúmenes de datos- Bigdata, ciencia de datos y análisis avanzados. Más información en la documentación oficial de Google BigQuery
Extra ¿Qué es OLAP?
Procesamiento analítico en línea, se caracteriza por un volumen relativamente bajo de transacciones. Las consultas son a menudo muy complejas e involucran agregaciones. Las aplicaciones OLAP son ampliamente utilizadas por las técnicas de Data Mining.
SI tiene algun comentario no duden en esribirme en la seccion de comentarios o en mis redes sociales.
Referencias:
