Tutorial para instalar y configurar ElasticStack: Elasticsearch, Logstash, Kibana, Beats
El objetivo de este tutorial es instalar y configurar todo el Elastic Stack para centralizar los logs de nuestras aplicaciones. Esto puede ser muy útil para identificar problemas en los servidores o aplicaciones, ya que permite realizar búsquedas en todos los logs desde un solo sitio, con esto podemos identificar problemas que abarcan varios servidores vinculando los logs durante un período de tiempo específico.
Los componentes que instalaremos son:
- Elasticsearch: Motor de búsqueda distribuido que almacena todos los datos recopilados.
- Logstash: Procesamiento de datos, para ingestar logs de múltiples fuentes simultáneamente y transformarlos antes de que se indexen en Elasticsearch.
- Kibana: Interfaz web para buscar en los logs y crear gráficas y dashboards.
- Beats: Agentes que transportan los datos, en este caso los archivos de logs hacia logstash para su procesamiento y posterior almacenamiento.
Para una introducción a todos los componentes y casos de uso de Elasicsearch puedes ver este post.
Flujo de datos
Este diagrama nos ayuda a entender el flujo que seguiran los logs de nuestras aplicaciones para ser centralizados usando el Elastic Stack:
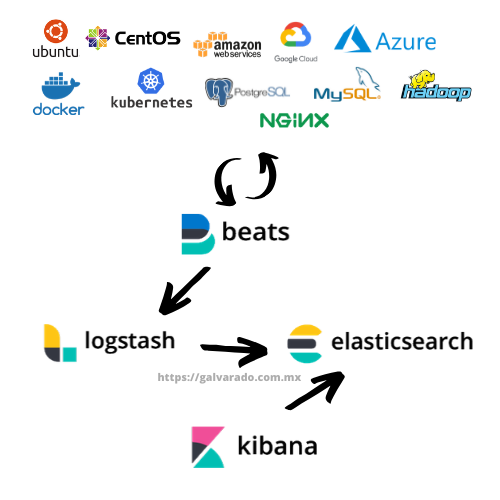
- Beats obtiene los logs de las aplicaciones y los envía a Logstash.
- Logstash recibe los datos, los transforma y los almacena en Elasticsearch.
- Elasticsearch indexa los datos, este es el repositorio donde se almacenarán los logs.
- Kibana accede a Elasticsearch para realizan consultas y analisis.
Prerequisitos
La versión que instalaremos será la 7.6 para todos los componentes del stack. Instalaremos Elasticsearch en una arquitectutra de alta disponibilidad, 3 nodos master y 3 nodos de datos (datanodes). Kibana y Logstash no se instalarán en alta disponibilidad. La instalación se realizará en máquinas virtuales, a continuación el inventario que usaré:
- 3 Máquinas virtuales como Elasticsearch Master Nodes
- 3 Máquinas virtuales como Elasticsearch Data Nodes
- 1 Máquina virtual para Logstash
- 1 Máquina virtual para Kibana
Todas las Máquinas virtuales que usaré tienen 2GB RAM y 2 CPUs. Los requerimientos de CPU, Memoria y Disco dependen de cada caso de uso, el dimensionamiento de RAM y CPU que elegí es para un laboratorio. Una referencia para producción se puede encontrar aquí.
La instalación se realizará usando el Sistema Operativo CentOS versión 8.
Nota: Para laboratorios todos los componentes se pueden instalar en la misma máquina virtual o incluso en un entorno local (laptop).
En cada servidor definiremos el archivo /etc/hosts para resolución de nombres de dominio local. Esto para no depender de crear registros DNS. Los hostnames son importantes porque la configuración de elasticsearch solicita hostnames y de esta manera se podrá resolver la IP de cada host.
En mi caso agregué al archivo /etc/hosts de cada nodo:
159.89.89.122 master01
159.89.88.78 master02
159.89.89.207 master03
159.89.89.222 data01
142.93.249.78 data02
159.89.89.72 data03
159.89.94.70 logstash
165.227.83.121 kibana
Prerequisito - Instalar Java 8
En todos las máquinas virtuales instalamos Java 8 pues es un requisito:
$ yum update
$ yum install java-1.8.0-openjdk
$ java -version
openjdk version "1.8.0_242"
OpenJDK Runtime Environment (build 1.8.0_242-b08)
OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)
Instalación Elasticsearch
Para instalar Elasticsearch podemos descargar el paquete desde el sito de Elastic o utilizar el repositorio RPM. Para la instalación mediante YUM utilizando el RPM:
1. Importar la clave PGP de Elasticsearch:
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2. Crear un archivo llamado elasticsearch.repo en el directorio /etc/yum.repos.d/:
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
3. Instalar con yum
$ sudo yum install --enablerepo=elasticsearch elasticsearch
Configuración Elasticsearch
Repetimos los pasos anteriores para todos los nodos de Elasticsearch, tanto los nodos master como los nodos de datos (datanodes).
Elasticsearch es un motor que está diseñado para ser distruibuido y ofrecer alta disponibilidad. Esto quiere decir que para crear el cluster tenemos opciones de configuración predefinidas y fácil de llenar.
La configuración del cluster se realiza mediante el archivo /etc/elasticsearch/elasticsearch.yml, modificamos los siguientes parametros:
- cluster.name: Nombre del cluster
- node.name: Nombre del nodo
- node.master: True o False, para determinar si un nodo es master node o es data node
- node.data: True o False, para determinar si un nodo es master node o es data node
- network.host: IP del nodo
- http.port: Puerto donde se habilita Elasticsearch, default 9200
- discover.seed_hosts: Lista de IPs de todos los nodos que forman el cluster (masternodes y datanodes)
- cluster.initial_master_nodes: Lista de hostnames de los nodos master del cluster
Por ejemplo en mi caso:
cluster.name: elasticsearchcluster
node.name: master01
node.master: true
node.data: false
network.host: 159.89.89.122
http.port: 9200
discovery.seed_hosts: ["159.89.89.122", "159.89.88.78", "159.89.89.207", "159.89.89.222", "142.93.249.78", "159.89.89.72"]
cluster.initial_master_nodes: ["master01", "master02", "master03"]
Nota: Distinguir entre las opciones node.master y node.data para designar el rol correcto para cada nodo. En este ejemplo tenemos 3 master nodes y 3 data nodes.
Una ves configurados todos los nodos del cluster, levantamos el servicio en cada uno. Primero habilitados el servicio para encienda automáticamente cuando el SO inicie:
$ systemctl daemon-reload
$ systemctl enable elasticsearch.service
Ahora, iniciamos elasticsearch:
$ sudo systemctl start elasticsearch.service
# sudo systemctl status elasticsearch.service
● elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled)
Active: active (running) since vie 2020-02-07 12:07:47 CST; 2 days ago
Comprobamos que el servicio quedó habilitado:
$ systemctl list-unit-files --state=enabled | grep elastic
elasticsearch.service enabled
Para comprobar que el cluster inició correctamente, hacemos una petición a la API de Elasticsearch:
$ curl http://[MASTER_IP]:9200
Salida esperada:
curl http://159.89.89.122:9200
{
"name" : "master01",
"cluster_name" : "elasticsearchcluster",
"cluster_uuid" : "twZSFiVsSzSYkfT8ZW2pVQ",
"version" : {
"number" : "7.6.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "7f634e9f44834fbc12724506cc1da681b0c3b1e3",
"build_date" : "2020-02-06T00:09:00.449973Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Instalación Logstash
Para la instalación mediante YUM utilizando el RPM:
1. Importar la clave PGP de Elasticsearch:
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2. Crear un archivo llamado logstash.repo en el directorio /etc/yum.repos.d/:
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3. Instalar con yum
$ sudo yum install logstash
Nota: Recuerda que uno de los prerequisitos es instalar Java. Revisa la sección anterior.
Configuración Logstash
La configuración se realiza mediante el archivo: /etc/logstash/logstash.yml, modificamos los siguientes parametros:
- http.host: IP del servidor
- http.port: Puerto del endpoint de metricas
Por ejemplo en mi caso:
http.host: "159.89.94.70"
http.port: 9600-9700
Una ves configurados los parametros, levantamos el servicio. Primero habilitamos el servicio para encienda automáticamente cuando el SO inicie:
$ systemctl daemon-reload
$ systemctl enable logstash.service
Ahora, iniciamos logstash:
$ sudo systemctl start logstash.service
$ sudo systemctl status logstash.service
● logstash.service - logstash
Loaded: loaded (/etc/systemd/system/logstash.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2020-02-19 19:45:16 UTC; 7s ago
Comprobamos que el servicio quedó habilitado:
$ systemctl list-unit-files --state=enabled | grep logstash
logstash.service enabled
En este punto ya está ejecutandose el proceso de logstash, pero aún no definimos ningun pipeline para recibir los datos que enviaran los agentes de beats ni tampoco hemos configurado almacenar los datos en elasticsearch.
En una sección posterior ( Configuración de Pipelines en Logstash) se detallará esta configuración. Por ahora nos basta con haber iniciado el proceso.
Instalación Kibana
Para la instalación mediante YUM utilizando el RPM:
1. Importar la clave PGP de Elasticsearch:
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2. Crear un archivo llamado logstash.repo en el directorio /etc/yum.repos.d/:
[kibana-7.x]
name=Kibana repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3. Instalar con yum
$ sudo yum install kibana
Nota: Recuerda que uno de los prerequisitos es instalar Java. Revisa la sección anterior.
Configuración Kibana
La configuración se realiza mediante el archivo: /etc/kibana/kibana.yml, modificamos los siguientes parámetros:
- server.port: Puerto donde se habilitará el servicio
- server.host: IP del servidor donde se expondrá el dashboard
- elasticsearch.hosts: los endpoints de elasticsearch. Colocamos aquí los nodos master.
Por ejemplo en mi caso:
server.port: 5601
server.host: 165.227.83.121
elasticsearch.hosts:["http://159.89.89.122:9200", "http://159.89.88.78:9200", "http://159.89.89.207:9200"]
Una ves configurados los parámetros, levantamos el servicio. Primero habilitamos el servicio para encienda automáticamente cuando el SO inicie:
$ systemctl daemon-reload
$ systemctl enable kibana.service
Ahora, iniciamos kibana:
$ sudo systemctl start kibana.service
$ sudo systemctl status kibana.service
$ status kibana.service
● kibana.service - Kibana
Loaded: loaded (/etc/systemd/system/kibana.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2020-02-19 20:09:53 UTC; 1s ago
Comprobamos que el servicio quedó habilitado:
$ systemctl list-unit-files --state=enabled | grep kibana
kibana.service enabled
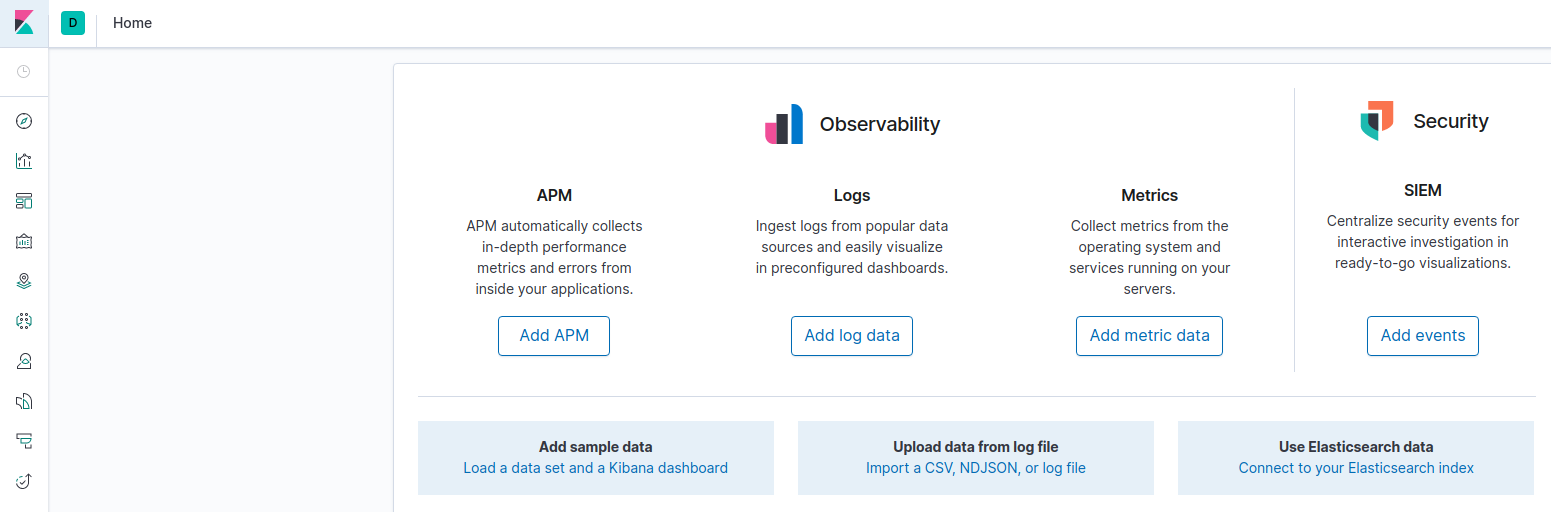
En este punto ya podemos entrar al dashboard, la página de bienvenida es esta:

En secciones posteriores veremos como visualizar los datos que estarán almacenados en elasticsearch. Por ahora nos basta con saber que kibana está instalado y funcionando.
Instalación Beats
En este punto tenemos el stack instalado y funcionando. Ahora veremos como llevar logs de servicios usando los agentes de beats.
Podemos instalar beats de multiples formas, dependiendo la pltaforma. Aquí lo haré desde el archivo RPM. Yo lo instalaré en CentOS como el resto de los componentes y el caso de uso que exploraré será enviar los logs de un servidor web apache. Si usas windows u otra distribución de Linux busca las instrucciones aqui en el enlance oficial del sitio de elasticsearch.
1. Importar la clave PGP de Elasticsearch:
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2. Crear un archivo llamado elstic.repo en el directorio /etc/yum.repos.d/:
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3. Instalar con yum
$ sudo yum install filebeat
Configuración Beats
La configuración se realiza mediante el archivo: /etc/filebeat/filebeat.yml, modificamos los siguientes parámetros:
- enabled: Para habilitar el servicio
- paths: Las rutas de los archivos de log que deseamos capturar. Podemos agregar varios, no solo uno.
- output.logstash: habilitamos esta opción para indicar que enviaremos los logs hacia logstash
- hosts: IP y puerto del host de logstash
Nota: la opción output.elasticsearch: debe estar deshabilitada, dejándola comentada, pues no enviaremos directamente hacia elasticsearch, si no a logstash.
Por ejemplo en mi caso:
enabled: true
paths:
- /var/log/httpd/access_log
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
#----------------------------- Logstash output --------------------------------
output.logstash:
#The Logstash hosts
hosts: ["159.89.94.70:5044"]
Una ves configurados los parámetros, levantamos el servicio. Primero habilitamos el servicio para encienda automáticamente cuando el SO inicie:
$ systemctl daemon-reload
$ systemctl enable filebeat.service
Ahora, iniciamos kibana:Ahora, iniciamos filebeat:
$ sudo systemctl start filebeat.service
$ sudo systemctl status filebeat.service
● filebeat.service - Filebeat sends log files to Logstash or directly to Elasticsearch.
Loaded: loaded (/usr/lib/systemd/system/filebeat.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2020-02-19 15:13:24 CST; 1min 8s ago
Configuración de Pipelines en Logstash
Cómo último paso, vamos a configurar un pipeline de procesamiento en logstash para que los archivos de log que se están enviando desde los agentes de beats sean recibidos, procesados y posteriormente enviados a su destino final, elasticsearch.
Para habilitar algún pipeline, este se e deben incluir en el archivo:
/etc/logstash/pipelines.yml:
- pipeline.id : apache
path.config: /etc/logstash/conf.d/apache-pipeline.conf
Y la definición del pipeline la escribimos entonces en /etc/logstash/conf.d/apache-pipeline.conf:
input {
beats {
port => "5044"
}
}
filter{
}
output {
elasticsearch {
hosts => [ "159.89.89.122", "159.89.89.78", "159.89.89.207"]
index => "apache_index"
document_type => "mytype"
}
}
Reiniciamos logstsash:
$ systemctl restart logstash.service
Podemos ver si inició correctamente el servicio y que pipelines están configurados en el log:
$ tail -f /var/log/logstash/logstash-plain.log
[2020-02-19T22:31:35,722][INFO ][logstash.outputs.elasticsearch][apache] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["//159.89.89.122"]}
[2020-02-19T22:31:35,809][INFO ][logstash.outputs.elasticsearch][apache] Using default mapping template
[2020-02-19T22:31:35,902][WARN ][org.logstash.instrument.metrics.gauge.LazyDelegatingGauge][apache] A gauge metric of an unknown type (org.jruby.specialized.RubyArrayOneObject) has been create for key: cluster_uuids. This may result in invalid serialization. It is recommended to log an issue to the responsible developer/development team.
[2020-02-19T22:31:35,926][INFO ][logstash.outputs.elasticsearch][apache] Attempting to install template {:manage_template=>{"index_patterns"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s", "number_of_shards"=>1}, "mappings"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}
[2020-02-19T22:31:35,951][INFO ][logstash.javapipeline ][apache] Starting pipeline {:pipeline_id=>"apache", "pipeline.workers"=>1, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>125, "pipeline.sources"=>["/etc/logstash/conf.d/apache-pipeline.conf"], :thread=>"#<Thread:0x1840e90e run>"}
[2020-02-19T22:31:38,367][INFO ][logstash.inputs.beats ][apache] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
[2020-02-19T22:31:38,424][INFO ][logstash.javapipeline ][apache] Pipeline started {"pipeline.id"=>"apache"}
[2020-02-19T22:31:38,495][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:apache], :non_running_pipelines=>[]}
[2020-02-19T22:31:38,688][INFO ][org.logstash.beats.Server][apache] Starting server on port: 5044
[2020-02-19T22:31:39,055][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
¿Que significa?
- Input: determina donde serán recibidos los logs, en este caso indicamos que se envian con beats y se reciben en el puerto 5044. Si deseamos tener multiples pipelines debemos definir un puerto para cada uno.
- Filter: Podemos filtrar los archivos para descartar algunos o para transformarlos y enriquecerlos. En este ejemplo no agregaremos ni modificaremos campos.
- Output: Indica hacia donde se debe enviar la información una vez filtrada y transformada. En este caso hacia elasticsearch. Usamos la IP de cada nodo master en el parámetro hosts. Indicamos el nombre del indice con el parámetro index. Usamos el tipo default dedocumento.
Visualización de logs en Kibana
Con esto tenemos centralizados los logs de apache, esto aplica para este nodo o si tuvieramos 20 nodos ejecutando apache y otras plataformas más pueden ser incluidas generando un pipeline para cada una, como en una arquitecrura 3Layer con Apache+MySQL+PHP. Teniendo todos los logs en un solo lugar nos facilitará la tarea de troubleshooting para solucionar errores cuando estos se presenten.
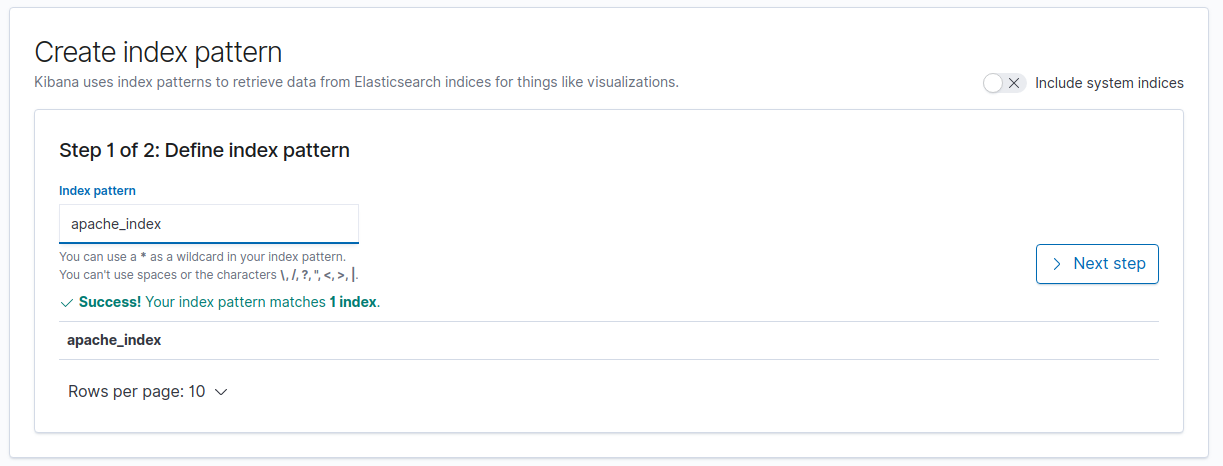
Para visualizar los logs en kibana debemos crear un index patter por cada indice:
- Vamos a la opción Connect to your Elasticsearch index:
- Colocamos el nombre del índice:
- Definimos el campo de ordenamiento:
Una vez creado, podemos ir a la sección “Discover”, ahí elegimos el índice y podremos visualizar los logs:
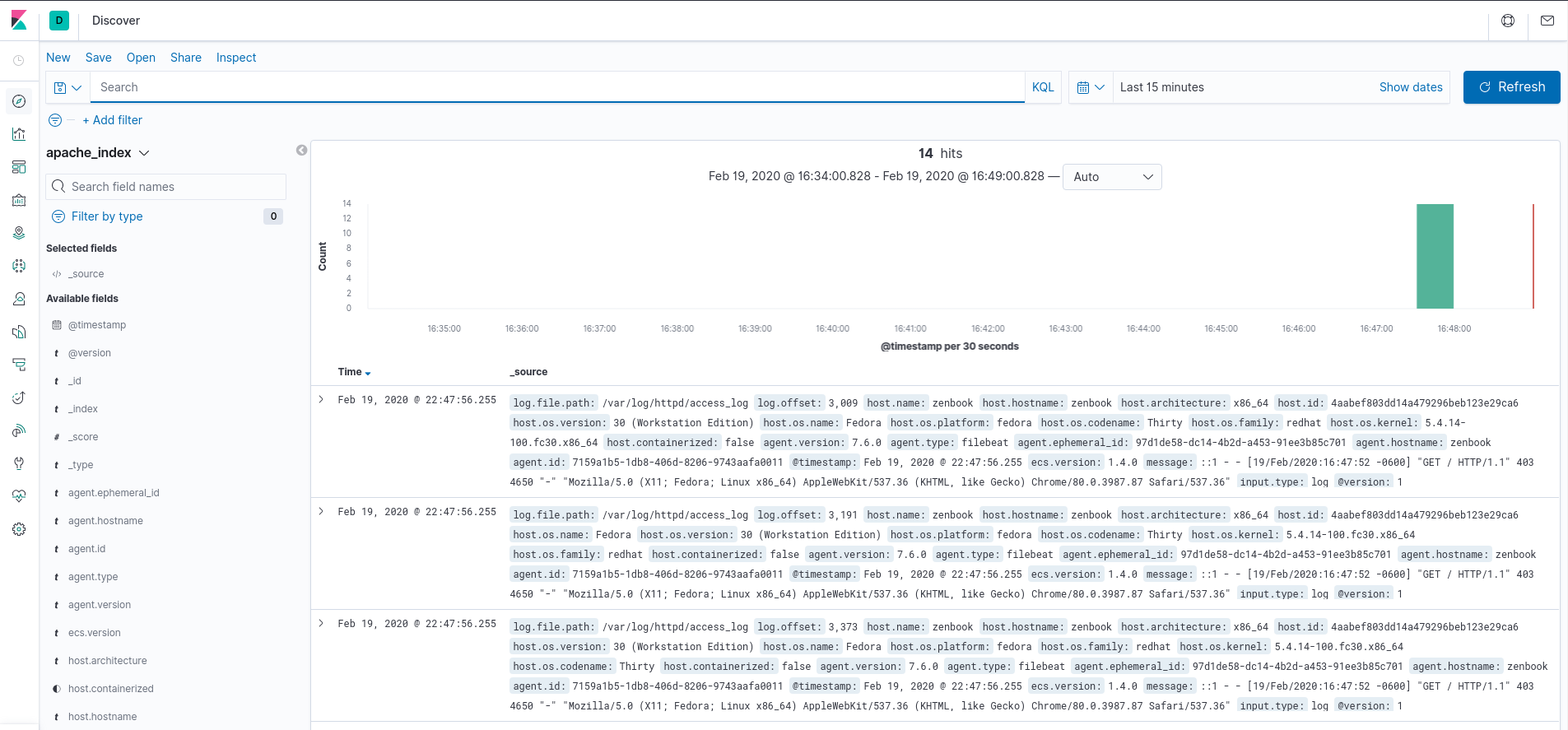
Si inspeccionamos uno de los registros podemos ver todos los campos:
{
"_index": "apache_index",
"_type": "mytype",
"_id": "r-2iX3ABMK33z-jz8TRe",
"_version": 1,
"_score": null,
"_source": {
"log": {
"file": {
"path": "/var/log/httpd/access_log"
},
"offset": 3009
},
"host": {
"name": "zenbook",
"hostname": "zenbook",
"architecture": "x86_64",
"id": "4aabef803dd14a479296beb123e29ca6",
"os": {
"version": "30 (Workstation Edition)",
"name": "Fedora",
"platform": "fedora",
"codename": "Thirty",
"family": "redhat",
"kernel": "5.4.14-100.fc30.x86_64"
},
"containerized": false
},
"agent": {
"version": "7.6.0",
"type": "filebeat",
"ephemeral_id": "97d1de58-dc14-4b2d-a453-91ee3b85c701",
"hostname": "zenbook",
"id": "7159a1b5-1db8-406d-8206-9743aafa0011"
},
"@timestamp": "2020-02-19T22:47:56.255Z",
"ecs": {
"version": "1.4.0"
},
"message": "::1 - - [19/Feb/2020:16:47:52 -0600] \"GET / HTTP/1.1\" 403 4650 \"-\" \"Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36\"",
"input": {
"type": "log"
},
"@version": "1",
"tags": [
"beats_input_codec_plain_applied"
]
},
"fields": {
"@timestamp": [
"2020-02-19T22:47:56.255Z"
]
},
"sort": [
1582152476255
]
}
Tenemos información del host que generó este log, el timestamp, el mensaje en el log y más información del agente que envia esta información. Todos estos campos son agregados por logstash. Si necesitamos agregar información podemos realizarlo en el pipeline en la sección de filter. En este ejemplo estamos guardando la información únicamente con los campos que logstash agrega por default. Más información de transformación con logstash la encuentras aquí.
Hasta aquí el tutorial, puedes seguir explorando todas las opciones que tiene kibana para crear dashboards y visualizaciones con los datos, combinando campos e indices.
Si quieres conocer más sobre los componentes puedes consultar la Introducción al Elastic Stack.
Si te fue útil, por favor comparte =)
