Beneficios y retos de la Infraestructura Inmutable + Tutorial: Packer, Ansible y Terraform

En los últimos años, la automatización se ha vuelto clave para la entrega de un producto de alta calidad.La clave aquí es: hazlo una vez, hazlo bien, hazlo replicable
En teoría, se puede aplicar cierto nivel de automatización a cualquier tarea de TI. Por lo tanto, la automatización puede incorporarse y aplicarse a cualquier elemento, desde la la red hasta la infraestructura, la implementación en la nube, los sistemas operativos, la gestión de la configuración y el despliegue de aplicaciones.
Dentro de la Automatización podemos encontrar la IaC o Infraestructura como código. Lo que nos lleva a hablar de Ia infraestructura Inmutable.
Todo el código del ejemplo en:

https://github.com/galvarado/immutable-infrastructure-demo
¿Encuentras una mejora? Bienvenidas las PR =)
Infraestructura Inmutable vs Mutable
En una infraestructura tradicional, los servidores se actualizan y modifican continuamente. Los administradores acceden a los servidores, actualizan paquetes , modifican los archivos de configuración e implementar nuevo código. En otras palabras, estos servidores son mutables; se pueden cambiar después de su creación.
Una infraestructura inmutable es otro paradigma de infraestructura en el que los servidores nunca se modifican después de su implementación. Si algo necesita ser actualizado, reparado o modificado de alguna manera, se aprovisionan nuevos servidores construidos a partir de una imagen común con los nuevos cambios para reemplazar los antiguos. Una vez validados, se ponen en uso y los antiguos se retiran.
Ejemplo: Liberamos una aplicación en Python con servidor web apache y base de datos MySQL. Para la segunda versión, mejoramos el rendimiento con nginx, así que instalamos en el servidor el nuevo software y deshabilitamos apache. El servidor es el mismo y ha sido manipulado.
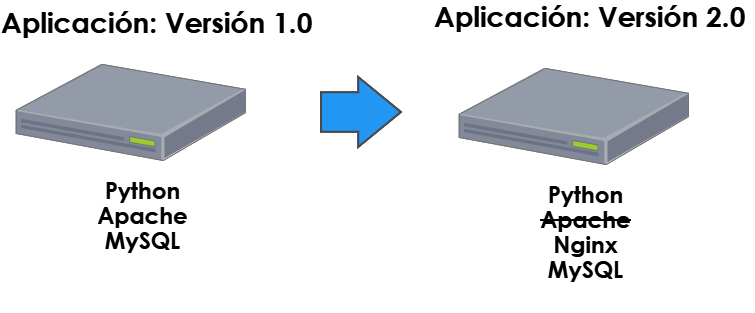
Con infraestructura inmutabe, en lugar de instalar nginx en el servidor, crearemos un nuevo servidor con este nuevo paquete y lo desplegaremos con la aplicación.
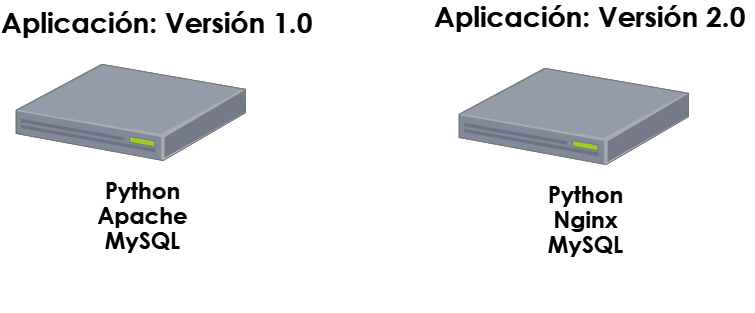
Cuando las pruebas sean satisfactorias, daremos de baja el servidor original y lo destruiremos, para colocar en producción el nuevo servidor.
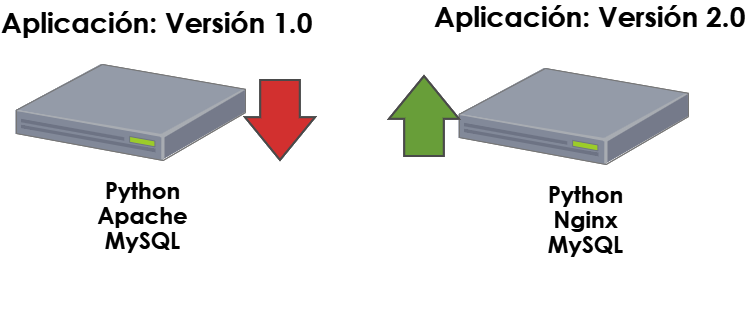
¿Vamos a reemplazar los servidores? Sí y la razón es sencilla: Es más fácil volver a partir de cero que lidiar con versiones y parches. ¿Qué pasaría si no logramos actualizar un paquete debido a algún error de red durante el despliegue? Podemos comenzar a tener “sucios” los ambientes. Sin embargo, si tenemos el proceso automatizado, crearemos nueva infraestructura y la reemplazaremos la primera, hasta estar seguros de que funciona el nuevo despliegue.
Obviamente hay algunas condiciones que debemos cumplir: si estamos manejando una base de datos, tendremos que migrarla al nuevo servidor. Lo mejor sería sacarla del servidor actual para no eliminar la información persistente y lograr tener una aplicación stateless. Luego, simplemente apuntaremos al nuevo servidor de base de datos cuando creemos un nuevo servidor de aplicación.
¿Cuáles son los beneficios de la infraestructura inmutable?
Sencillo: la confiabilidad. Ya sea que esté se esté desplegando contenido en sistemas bare metal o en la nube en servicios como AWS, GCP o Azure, siempre existe el riesgo de que algo falle y las plataformas deban restaurarse rápidamente. En estas situaciones, tener copias de seguridad está bien, pero normalmente el proceso para recuperarlas no está tan bien probado como debería y, puede llevar muchísimo tiempo.
Una máxima es:
Los respaldos funcionan, hasta que los necesitas restaurar.
Sin embargo, si tenemos sistemas inmutables respaldados por procesos de automatización de uso frecuente, ya tenemos integrada la recuperación ante desastres. La infraestructura se vuelve desechable y podemos recrear entornos de forma rápida y sencilla.
La infraestructura inmutable juega un papel muy importante en el desarrollo de software, ya que en lugar de cambiar parte de la infraestructura, ahora podemos crear una nueva con las nuevas características necesarias y desechar la antigua. La nube nos ha brindado las herramientas para hacerlo más barato y eficiente, de modo que todo tipo de sistemas, desde sitios web pequeños hasta plataformas internacionales a gran escala puedan beneficiarse.
¿Dónde se puede aplicar la infraestructura inmutable? ¿Cuáles son los inconvenientes ?
La automatización inspira confianza tanto en el software como en la arquitectura en la que se ejecuta. Se puede aplicar en todas partes, desde el arranque del entorno de desarrollo y los sistemas de integración continua hasta los sistemas eb producción. Con una planificación cuidadosa, podemos recrear sistemas completos o aplicar actualizaciones a entornos con un solo clic y reproducir de forma fiable los mismos resultados una y otra vez.
Para usar este enfoque de manera eficiente debemos:
- Automatizar los despliegues de aplicaciones.
- Automatizar el aprovisionamiento rápido de servidores en un entorno de nube.
- Usar arquitecturas y aplicaciones que usan soluciones externas (datastore o bases de datos) para manejar los estados, es decir, son stateless.
Todas las actualizaciones (deploy) deberán pasar por un proceso automatizado. Sin una automatización bien probada, los despliegues suelen ser experiencias dolorosas, que provocan miedo y que consumen mucho tiempo. Sin embargo, cuando uno tiene confianza en la automatización y se puede estar seguro del estado de los sistemas en todo momento, los despliegues se vuelven simples y pueden realizarse muchas veces al día.
Algunas inversiones iniciales en la automatización de la infraestructura siembran las semillas que permitirán cosechar grandes beneficios en tiempo y esfuerzo.
Esta es una herramienta de enorme importancia en el arsenal del desarrollo de software moderno.
Estoy convencido ¿Cómo lo aplico?
Las herramientas para esto son:
- Packer para construir una imagen del servidor a desplegar.
- Ansible para el aprovisionamiento de software e instalación de dependencias
- Terraform para orquestar y crear la infraestructura en la nube.
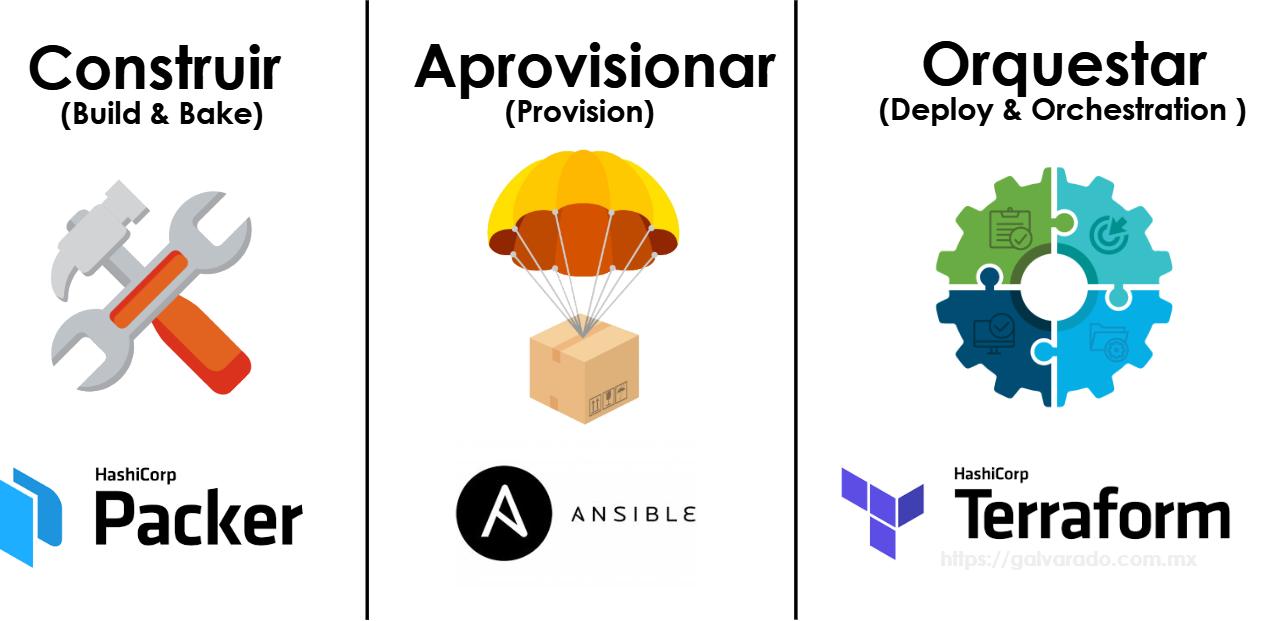
Por lo tanto, en los proyectos donde queramos ir por el paradigma de la infraetructura inmutable deberiamos integrar estas 3 herramientas. En el repositorio deberíamos tendremos un directorio con el template de Packer para construir la imagen del servidor, playbooks de ansible que instalarán la aplicación y cualquier dependencia y templates de terraform que nos permiten crear la infraestructura en la nube, a partir de la imagen recién construida.
Para poner en práctica los conceptos, desplegaremos un sitio sencillo en DigitalOcean, pero puedes usarlo para cualquier aplicación escrita en Python, Java, PHP, Go, NodeJS, etc. Lo que cambia es el proceso de despliegue de cada aplicación y sus dependencias, pero en todos los caso: Construimos la imagen, la aprovisionamos y la desplegamos en la nube.
Si quieres saber más de Infraestructura como código y conceptos de Terraform te recomiendo este post: Tutorial: Infraestructura como código con Terraform. Sobre Ansible, este post explica como automatizar toda la instalación de Wordpress con Ansible. Sobre conceptos de Packer y como se puede automatizar la construcción de imágenes puedes leer este post.
Tutorial
Puedes clonar el ejemplo completo en el siguiente repositorio.
Lo explico paso a paso a continuación:
Ansible
Creamos el playbook que aprovisiona el software:
---
- name: 'Bootstrap server and Install application'
hosts: default
tasks:
- name: Add epel-release repo
yum:
name: epel-release
state: present
become: yes
- name: Install nginx
yum:
name: nginx
state: present
become: yes
- name: start nginx
service:
name: nginx
state: started
enabled: yes
become: yes
- name: "create html directory"
become: yes
file:
path: /usr/share/nginx/html/app
state: directory
mode: '0775'
- name: "sync app code"
become: yes
synchronize:
src: ../app/
dest: /usr/share/nginx/html/app
archive: no
checksum: yes
recursive: yes
delete: yes
- name: Update default document root
become: yes
replace:
path: "/etc/nginx/nginx.conf"
replace: "root /usr/share/nginx/html/app;"
regexp: "root /usr/share/nginx/html;"
notify: restart nginx
handlers:
- name: restart nginx
service:
name: nginx
state: restarted
become: yes
Este playbook instala nginx, realiza la configuración de la aplicación, sincroniza el código de la misma en el servidor y reinicia el servicio de nginx.
Packer
Creamos un template de packer que construye una imagen de Centos 8 en Digital Ocean. Indicamos como provisioner el playbook de ansible que instala las dependencias y la aplicación en sí.
El template define una VM de 1vcpu y 1GB RAM para la construcción de la imagen y usa la región NCY1.
{
"variables": {
"do_api_token": "{{env `DIGITALOCEAN_API_TOKEN`}}"
},
"builders": [{
"type": "digitalocean",
"api_token": "{{user `do_api_token`}}",
"size": "s-1vcpu-1gb",
"region": "nyc1",
"image": "centos-8-x64",
"droplet_name": "packer-centos8-x64",
"snapshot_name": "image-by-packer-centos8-x64-{{timestamp}}",
"ssh_username": "root",
"private_networking": true,
"monitoring": true
}],
"provisioners": [{
"type": "ansible",
"playbook_file": "../ansible/bootstrap.yml"
}]
}
Para aprovisionar la imágen es necesario contar con una cuenta en DigitalOcean. Una vez tengamos la cuenta hay que darle acceso a Packer para que pueda crear la imagen por nosotros.
Para esto es necesario generar un token, ir a la página https://cloud.digitalocean.com/account/api/tokens y crear un token:

Copiamos el token y lo exportamos como variable de entorno.
export DIGITALOCEAN_API_TOKEN=4059d45e5a75de0f24fe8f2ec678062e5cf8d66db885cdf4826befb30557d2gh
Con esto, ya podemos ejecutar Packer:
$ cd packer
$ packer build centos8-digitalocean.json
Cuando este termine, debemos ver la imagen recién creada en Digitla Ocean en: https://cloud.digitalocean.com/images/snapshots/droplets.
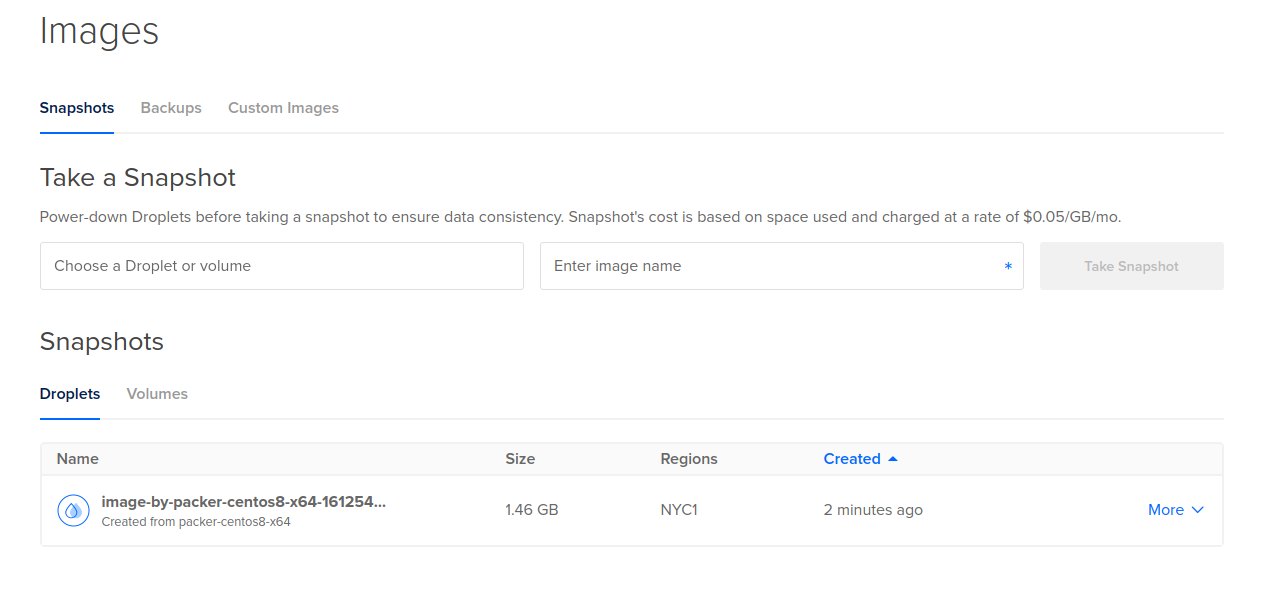
Esta imagen es la que usará terraform para crear el servidor en la nube y ya cuenta con todas las dependencias y la aplicación. Así que en cualquier proceso de restauración, podemos siempre crear nuevos servidores a partir de esta imagen.
Terraform
En el template de terraform que crea el servidor, indicamos una expresión regular para que este busque la imagen que recién creo Packer.
variable "do_token" {}
variable "droplet_ssh_key_id" {}
variable "droplet_name" {}
variable "droplet_size" {}
variable "droplet_region" {}
# Configure the DigitalOcean Provider
provider "digitalocean" {
token = var.do_token
}
# Get snapshot name
data "digitalocean_droplet_snapshot" "ubuntu2004-packer-image" {
name_regex = "^image-by-packer-centos8"
region = "nyc1"
most_recent = true
}
# Create a web server
resource "digitalocean_droplet" "server-by-terrraform" {
image = "${data.digitalocean_droplet_snapshot.ubuntu2004-packer-image.id}"
name = var.droplet_name
region = var.droplet_region
size = var.droplet_size
monitoring = "true"
ssh_keys = [var.droplet_ssh_key_id]
}
Creamos el archivo de variables. En la ruta raíz del código de terraform creamos un archivo llamado terraform.tfvars y colocamos las siguientes variables:
do_token: must have the token created in the previous step.
droplet_ssh_key_id: The id of the key in DigitalOcean that will be used to connect to the virtual machine
droplet_name: The name of the droplet in DigitalOcean
droplet_size: The size of the droplet to use
droplet_region: The region where the droplet will be deployed
Para obtener los valores de la región, la clave ssh, el nombre de la imagen y el tamaño de la máquina virtual, instala el cliente de línea de comandos de Digital Ocean: https://www.digitalocean.com/docs/apis-clis/doctl/
Por ejemplo, para listar las llaves SSH en la cuenta:
$ doctl -t $DIGITALOCEAN_API_TOKEN compute ssh-key list
Para listar las regiones:
$ doctl -t $DIGITALOCEAN_API_TOKEN compute region list
Para listar los tamaños de VM:
$ doctl -t $DIGITALOCEAN_API_TOKEN compute size list
Estos son los valores que también está usando packer.
Nota: El tamaño de la VM puede diferir entre el tamaño que deseamos que use packer para construir la imagen y el que será el tamaño final de la VM ya desplegada.
terraform.tfvars
do_token = "xxxdfc7f164a7001f76048313b0970bd46092f20569b9780ac242b00c9a7axxx"
droplet_ssh_key_id = "1632017"
droplet_name = "server-by-terraform"
droplet_size = "s-1vcpu-1gb"
droplet_region = "nyc1"
Para desplegar la VM con la imagen creada por Packer y aprovisionada por Ansible:
$ cd terraform
$ terraform init
$ terraform plan
$ terraform apply
Cuando terraform termine, veremos el servidor recién creado:

Y debemos ver la aplicación desplegada en la IP que obtuvimos:
El siguiente paso es realizar un pipeline con una herramienta de CI/CD como Jenkins que maneje todo el flujo, para no ejecutar los comandos uno a uno. Esto lo revisaremos en el próximo post.
Si te pareció útil, por favor comparte. Si tienes dudas no dejes de escribir en los comentarios.
Referencias:
