Almacenamiento persistente para contenedores: Red Hat OpenShift + Red Hat Gluster Storage

Cada vez es más común encontrar en el ecosistema aplicaciones construidas y entregadas en contenedores. Una de las primeras dudas cuando se trata de migrar a este tipo de arquitecturas es el tema del almacenamiento ya que los contenedores son efímeros, no persistentes, si el proceso del contenedor muere, todos los datos de las aplicaciones residentes se pierden.
Las aplicaciones críticas para el negocio requieren que los datos permanezcan disponibles más allá de la vida útil del contenedor. La capa de almacenamiento entonces debe ser elástica, aprovisionada fácilmente y orquestada.
En esta ocasión decidí escribir acerca de las diferentes estrategias que se pueden seguir para construir un ambiente de OpenShift con almacenamiento persistente provisto por Gluster.
El almacenamiento local no es suficiente
Al igual que con las VMS, algunas aplicaciones deben conservar sus estado, datos y configuración. Un ejemplo es un contenedor de base de datos. Este necesita almacenamiento persistente para su almacén de datos (donde la base de datos real vive).
El primer ejemplo que aprendemos cuando comenzamos con Docker, entorno al almacenamiento, es que podemos usar el host y su almacenamiento, como volumen para nuestros contenedores. Finalmente los datos terminan siendo persistentes en el host.
Pero cuando usamos una tecnología de orquestación, que es un ejemplo más real donde en realidad no hay un host sino varios que son orquestados, el almacenamiento local no es suficiente porque si el contenedor se mueve a otro host, pierde acceso a los datos. Por tanto se requiere una capa de almacenamiento subyacente para proporcionar características empresariales como las que están disponibles para las aplicaciones en entornos virtualizados.
Con el fin de abordar el problema de aprovisionamiento, OpenShift permite entregar volúmenes desde una amplia gama de plataformas usando plugins. Esto garantiza que no importa donde se ejecute el contenedor (dentro del cluster) podrá acceder a su volumen de almacenamiento persistente. Los volúmenes persistentes son conexiones que apuntan a la capa de almacenamiento subyacente.
La capa subyacente en este caso para OpenShift es Gluster y la literatura entorno al tema distingue 2 tipos de almacenamiento:
Almacenamiento para contenedores
También conocido como “Container ready storage”, esto es esencialmente una configuración donde el almacenamiento es expuesto a un contenedor desde un punto de montaje externo a través de la red.
La mayoría de soluciones, incluyendo SDS, SAN o NAS se puede configurar de esta manera utilizando interfaces estándar. Sin embargo, esto no ofrece valor adicional ya que pocos almacenamientos tradicionales tienen APIs que pueden ser aprovechados por Kubernetes para otorgar aprovisionamiento dinámico. Más tarde definimos qué es el aprovisionamiento dinámico.
Almacenamiento en contenedores
También conocido como “Container native storage” es almacenamiento desplegado dentro de contenedores, junto a las aplicaciones que se ejecutan en contenedores.
Teniendo los contenedores de almacenamiento en el mismo plano de gestión, se pueden ejecutar las aplicaciones y la plataforma de almacenamiento en el mismo conjunto de infraestructura, lo que reduce el gasto en infraestructura.
Adicional mente los desarrolladores se benefician al poder proveer a las aplicaciones almacenamiento que es altamente elástico y amigable para estos entornos. Con esta solución tenemos almacenamiento con aprovisionamieto dinámico para los contenedores. No es la única manera de obtener el aprovisionamiento dinámico, pero es una de las vías mejor integradas.
¿Qué es el aprovisionamiento dinámico de volúmenes?
Permite que cualquier persona con acceso a la consola de gestión de OpenShift pueda crear volúmenes de almacenamiento bajo demanda. Con esto, los desarrolladores pueden aprovisionar el almacenamiento por su cuenta sin la necesidad de conocer la tecnología subyacente. Los desarrolladores ya no tienen que enviar una solicitud de almacenamiento a un administrador y esperar a que sea atendida.
Sin almacenamiento aprovisionado dinamicamente, tenemos 2 inconvenientes: La tarea de crear un volumen de almacenamiento usualmente lo hace otro administrador especialista de esta capa, entonces se tiene una dependencia y un cuello de botella en cuanto a la capacidad de atener estas peticiones.
El otro tema es que con el aprovisionamiento estático, los desarrolladores tienen que estimar la cantidad de almacenamiento que van necesitar y solicitarlo a la administrador y cambiar este espacio, requeriría una nueva solicitud.
Red Hat Gluster Storage
Red Hat Gluster Storage puede configurarse para proporcionar almacenamiento persistente y aprovisionamiento dinámico para OpenShift. Puede utilizarse desplegado en contenedores, esto sería “container native " y sería una configuración convergente . La otra alternativa es desplegarlo sin estar en contenedores, instalado en sus propio nodos, esto sería “container ready” y sería una configuración de gluster en modo independiente. Podemos identificar otra variante del modo independiente, llamada Standalone. **Está última alternativa llamada standalone no ofrece almacenamiento con aprovisionamiento dinámico.
1. Modo convergente
Configuración de un nuevo clúster de GlusterFS alojado de forma nativa. En este escenario, los pods de GlusterFS se implementan en nodos en el clúster OpenShift que están configurados para proporcionar almacenamiento.
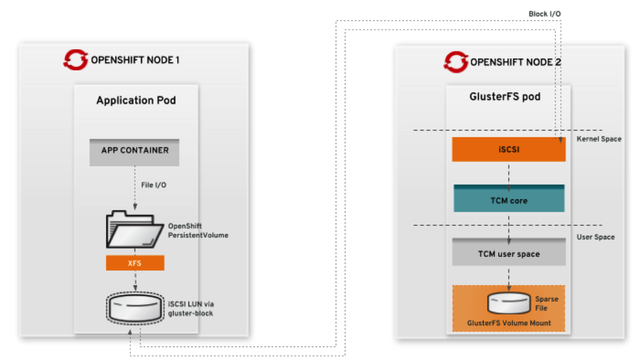
A continuación la arquitectura de la solución en modo convergente:
2. Modo independiente
Configurando un nuevo cluster externo de GlusterFS. En este escenario, los nodos del clúster tienen el software GlusterFS preinstalado pero aún no se han configurado. El instalador se encargará de configurar los clústers para su uso por las aplicaciones OpenShift.
3. Modo standalone
Usando un cluster existente de GlusterFS. En este escenario, se supone que uno o más clústeres de GlusterFS ya están configurados. Estos clústeres pueden ser nativos o externos, pero deben ser gestionados por el servicio heketi.
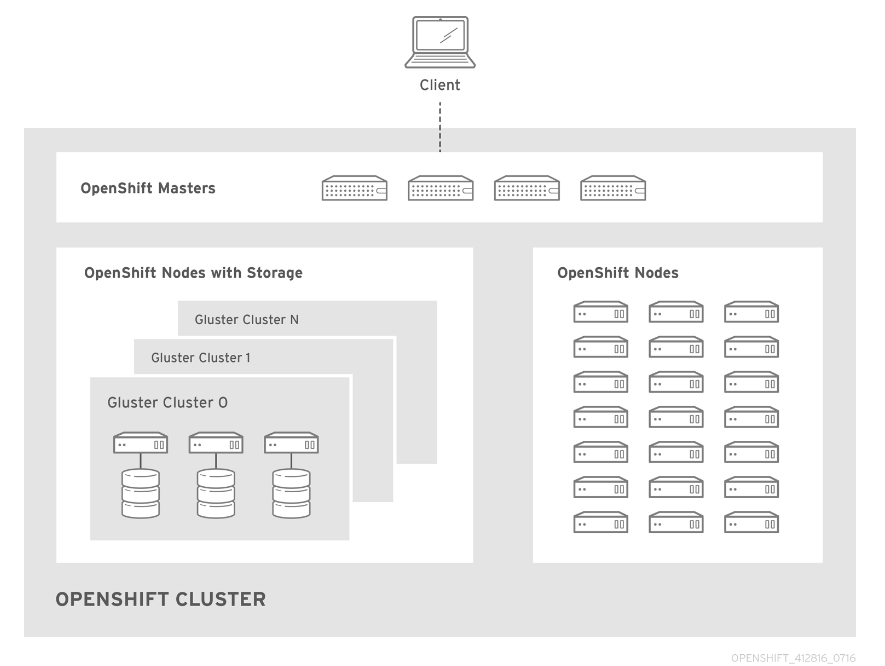
A continuación la arquitectura de la solución en modo independiente y standalone:
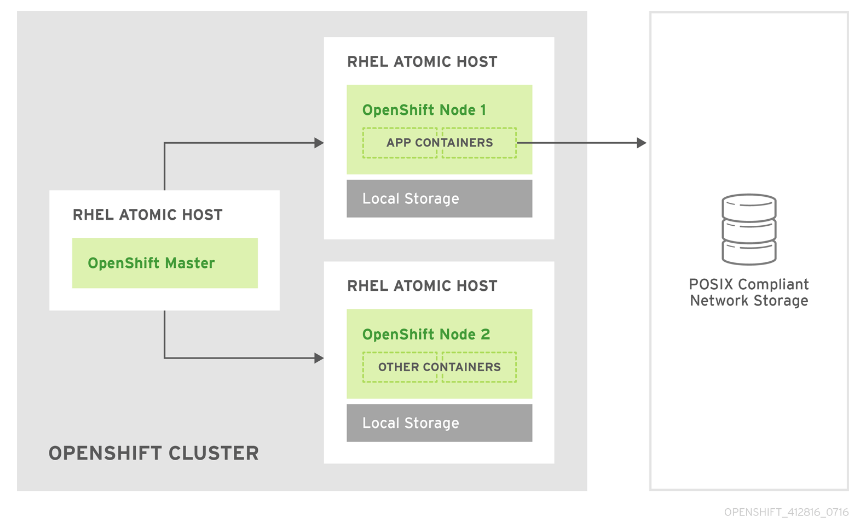
No solo Kubernetes y Red Hat Gluster Storage son importantes para la gestión dinámica del volumen de almacenamiento, en realidad Heketi y gluster-kubernetes son proyectos que habilitan esta solución. El proyecto Heketi proporciona una API RESTful y una CLI para aprovisionamiento dinámico de volúmenes. Heketi soporta cualquier número de clusters de almacenamiento de Red Hat Gluster. El proyecto gluster ‐ kubernetes permite administrar la implementación y configuración de GlusterFS en Kubernetes y gestiona automáticamente el hardware.
Podemos concluir que el aprovisionamiento dinámico es una parte importante en toda la solución de orquestación de contenedores y elegir una capa que permita esto será determinante en la manera de trabajar sobre la plataforma.
Referencias:
- https://docs.openshift.com/container-platform/3.10/install_config/persistent_storage/persistent_storage_glusterfs.html
- https://github.com/openshift/openshift-ansible/tree/master/roles/openshift_storage_glusterfs
- https://www.redhat.com/es/resources/solving-persistent-storage-for-containers-infographic
- https://www.redhat.com/es/technologies/cloud-computing/openshift-container-storage
Si te es de utilidad, por favor comparte =)
